
Machine learning and analytics of big data is a rapidly growing field, but learning how to analyze these items has had a steep learning curve, until now. Machine learning is nothing new, and has used a set of standard algorithms for evaluating datasets have not changed. With cloud computing and cheap storage it is now possible to take advantage of these algorithms and apply it to large data sets. Microsoft has created a visual tool for creating a experiments using machine learning techniques to evaluate the data, and take out the hurdles that once stopped users from utilizing machine learning.
Classification is a type of supervised learning where a set of features is evaluated then classified based on what those features represent. The more features and items included in the dataset, the more accurate the comparison. In this example, the classification technique will be used to train and evaluate the datasets to create a functioning web service that uses machine learning.
Classification Example

Setup Project
To begin, a new project needs to be setup. A project will classify the models, experiments, and web services for referencing later. A project does not tie down a data set or model and which can be used interchangeably between projects. To begin, select the Projects tab on the left, then select new at the bottom of the screen.
Then select empty project from the list of project.
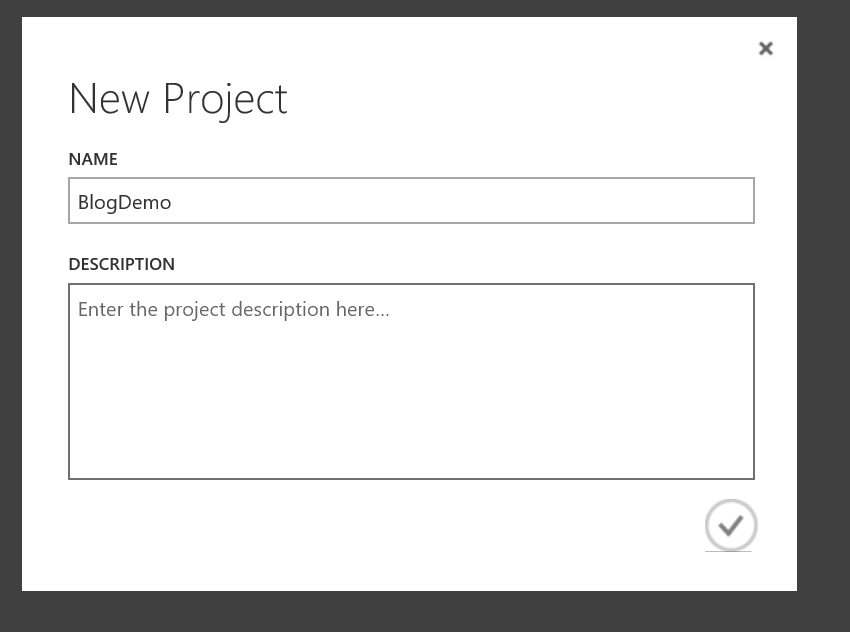
A modal will appear where a name can be added to project and add a description. Once the project is named click the check, the project is created.
Clean data
For this example, classifications of different Iris species will be used to train the model. The models were obtained from archive.ics.uci.edu for training, and the test set is from Wikipedia. Both data sets can be found can be found below.
Before training the model, the data must be cleaned so that the test and training data contain the same feature headings and species class name. Once the headings in the data are changed, the classification/species names need to be checked. It is important that the training set and test set both use the same names for classification; otherwise it will produce 6 classifications and the wrong species returned in the results.
Training Set
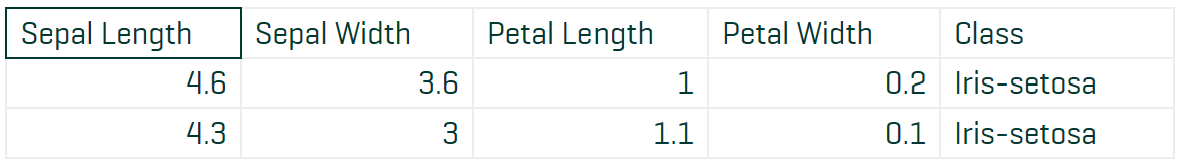
Testing Before Cleanup

Testing After Cleanup

Upload datasets
Now that the data is cleaned, the datasets can be upload to the project for testing. To do this, go to the datasets tab and click new.
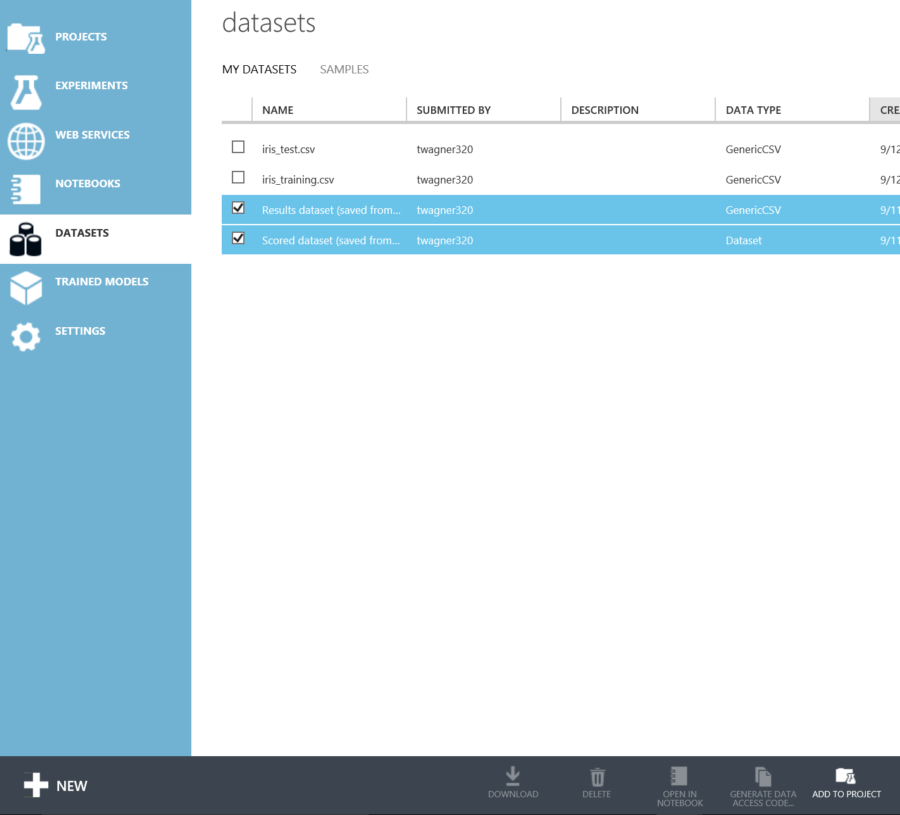
From the menu, select From Local File

Upload each dataset, and enter a name.
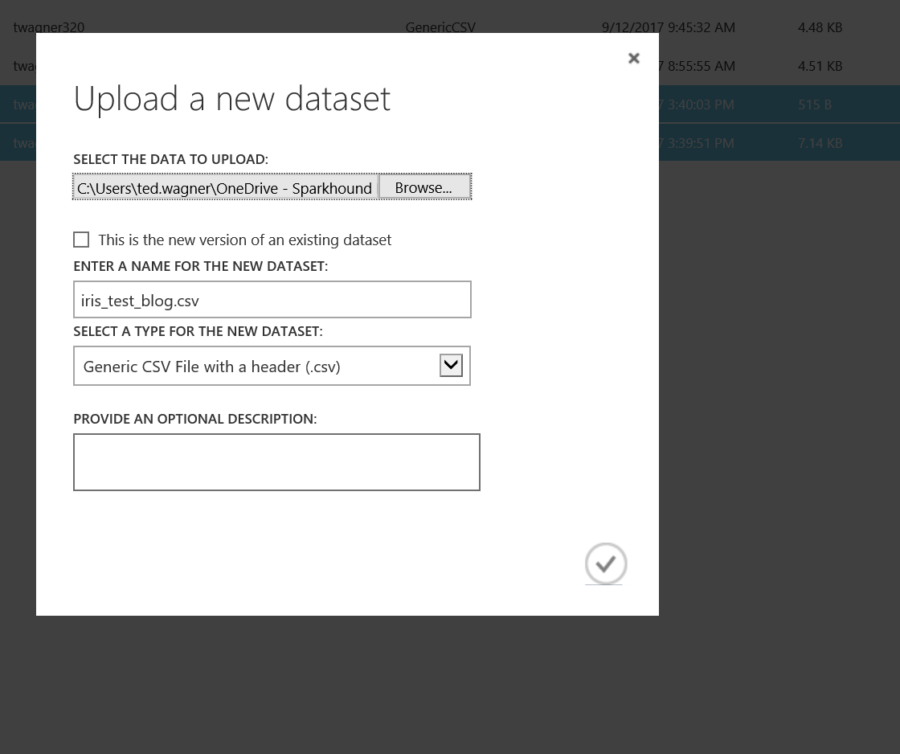
Create experiment
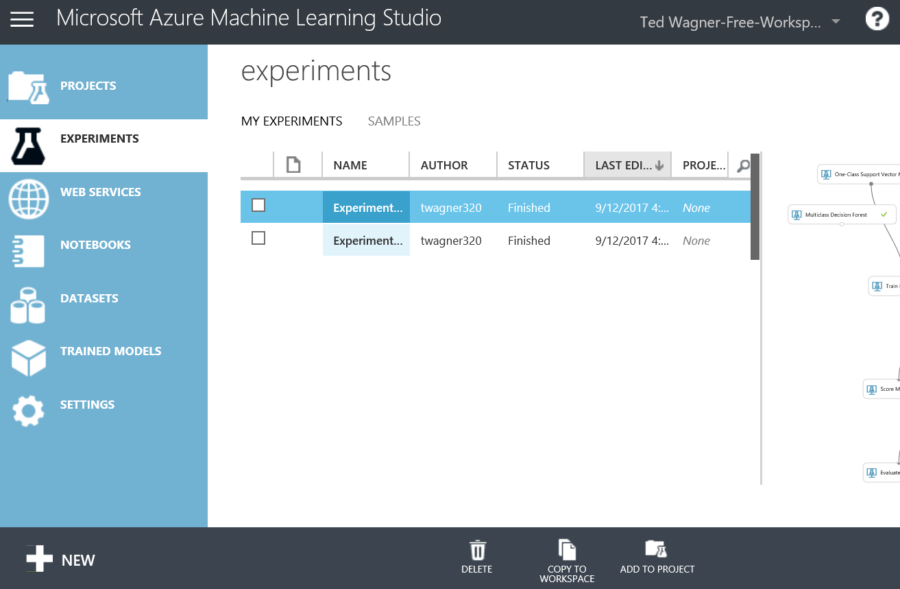
An experiment is where the datasets will train and evaluated to view the accuracy before publishing the results to a web service. To start a new experiment, click the experiment tab and select new at the bottom.
To begin, select blank experiment to create a blank canvas to evaluate the models.
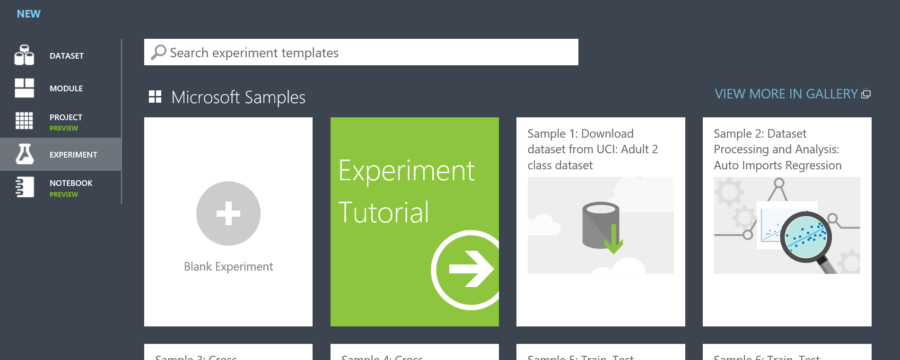
When completed, the screen should now look like this.
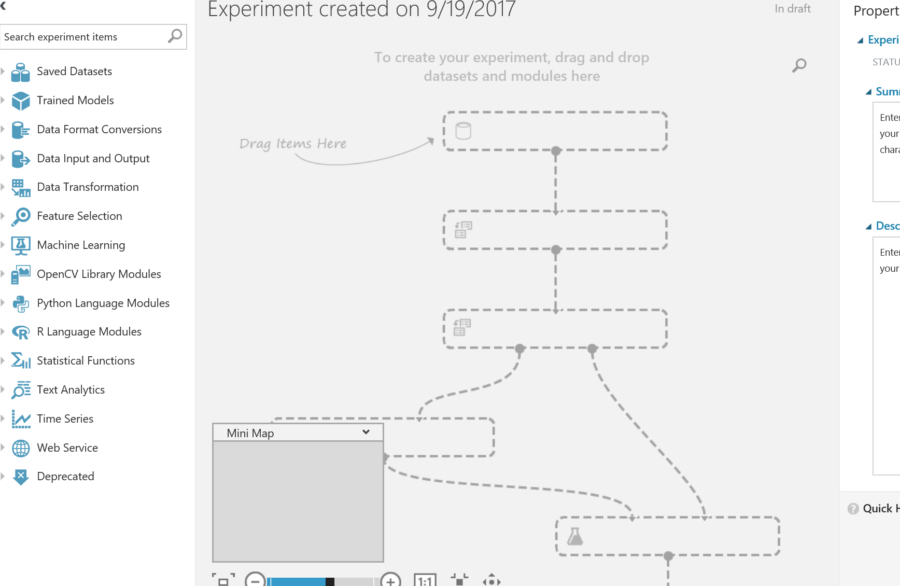
To start the experiment, data is needed to evaluate. Drag the saved datasets from the “Saved Datasets” section onto page.
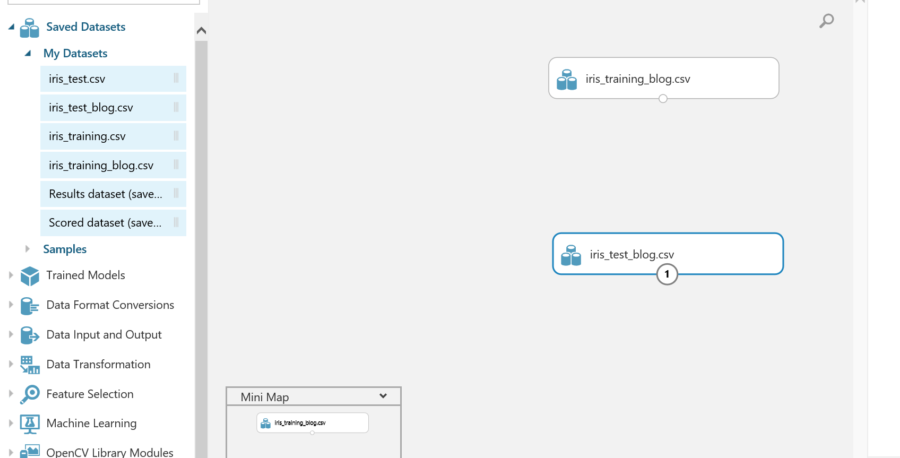
The next step is to train a model. This can be found in the machine learning tab. Expand the machine learning tab which will give the options for the model. Since the first step is to train the model, expand the training section and drag the Train model action to the page.
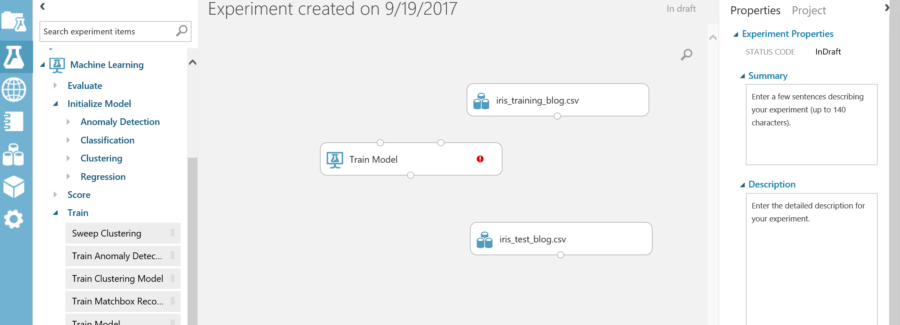
Notice the 3 connection points, and a red exclamation mark. The train model action is looking for a dataset and a type of model to initialize the training. The other connection point is the output of the trained model. In order to train the model, an initialization model must be selected. The initialization model represents the type of machine learning technique that will be used to train the model. Since this is a classification model, expand classification. Within the classification section there will be multiple choices. Since the datasets have more than two features, a multiclass action should be used. For this example, the multiclass Neural Network will be the initial model used for training. Drag the Multiclass Neural Network to the page and connect it and the data source to the train model action.
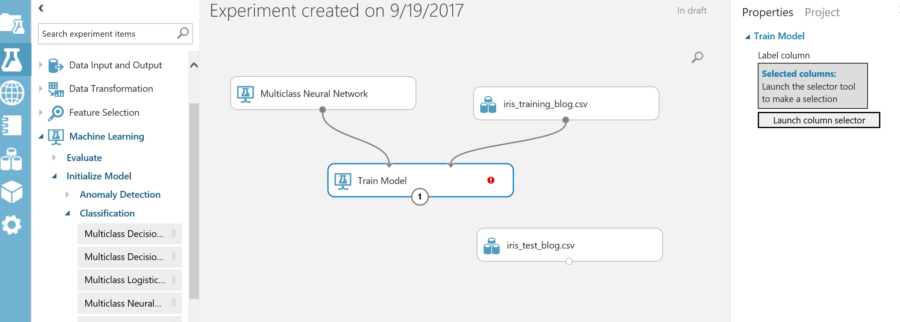
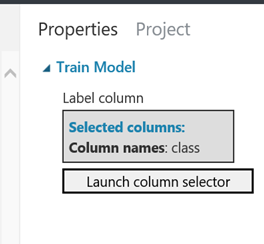
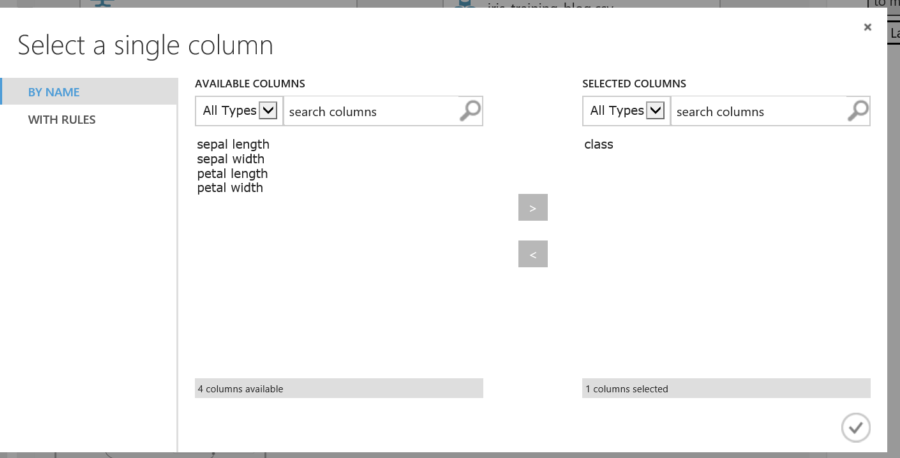
Even after connecting the training technique and dataset to the model, there is still a red exclamation. This is because the classification name column associated with the dataset has not been assigned to the training model. On the right side of the screen, there is a launch column selector. This is for selecting the column that holds the classification name. Launch the selector, and choose the column named “class”.
Now that the training model is setup, the model needs to be scored to make sure it gives an accurate score. To do this expand the “Machine Learning” section and then expand score then drag the Score Model action to the page. Once it is on the page connect the test dataset and the train model to the top of the evaluate model.
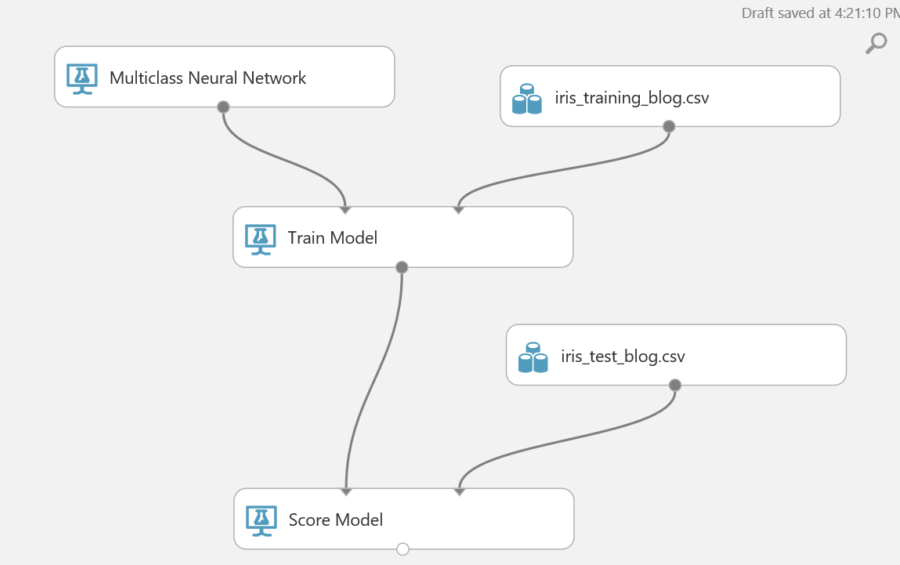
Finally, the model needs to be evaluated. This will give the results of the training and how the predictions are weighted. There is the option to attach an additional dataset. This will allow evaluation against another data set.
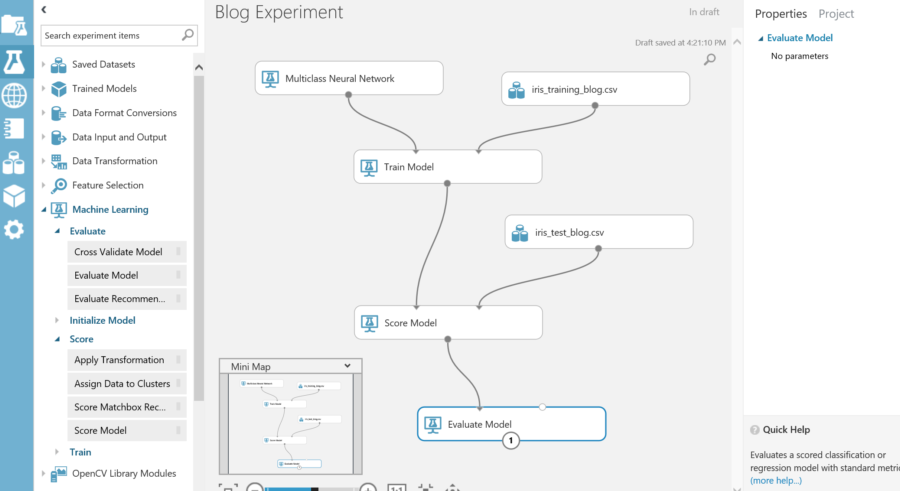
Run experiment
Now that the experiment setup, it is time to run it. Click save and run at the bottom of the experiment.

A successful training will show all green checks on each stage of the experiment.
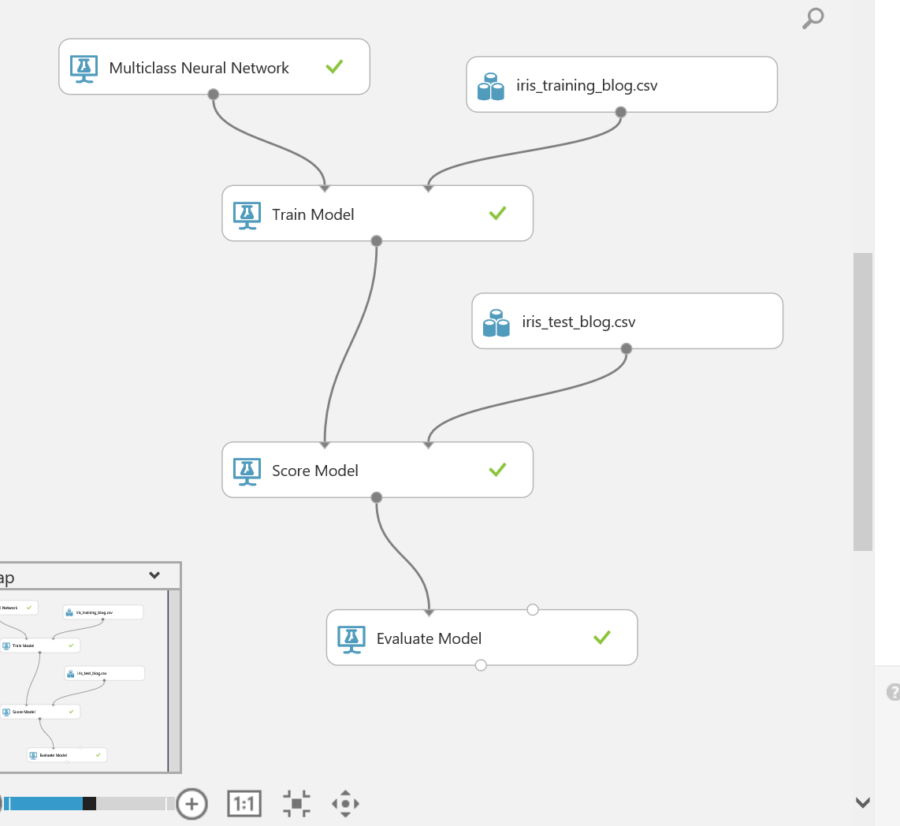
View results
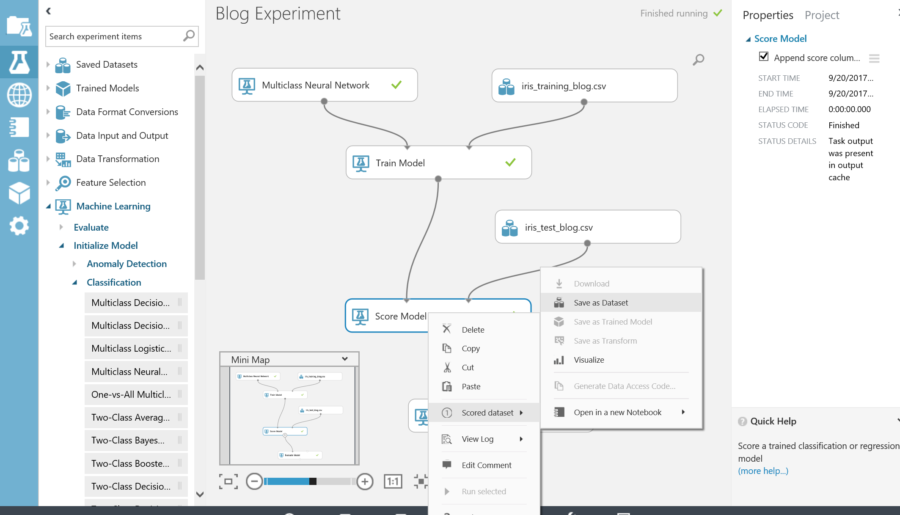
The results of each step can be viewed by right-clicking on the action. In the menu a visualization section will appear to view the results.
The score view shows up what the model predicted each line item in the test data represented and how strongly it felt its guess was correct.
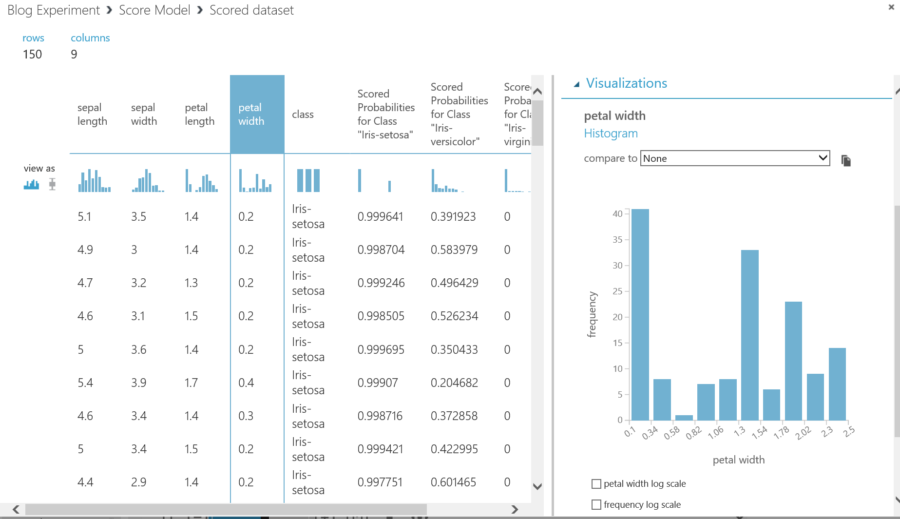
Score View
The evaluation view gives an overall accuracy percentage based on the test data, and what guesses were correct and what each guess is weighted.
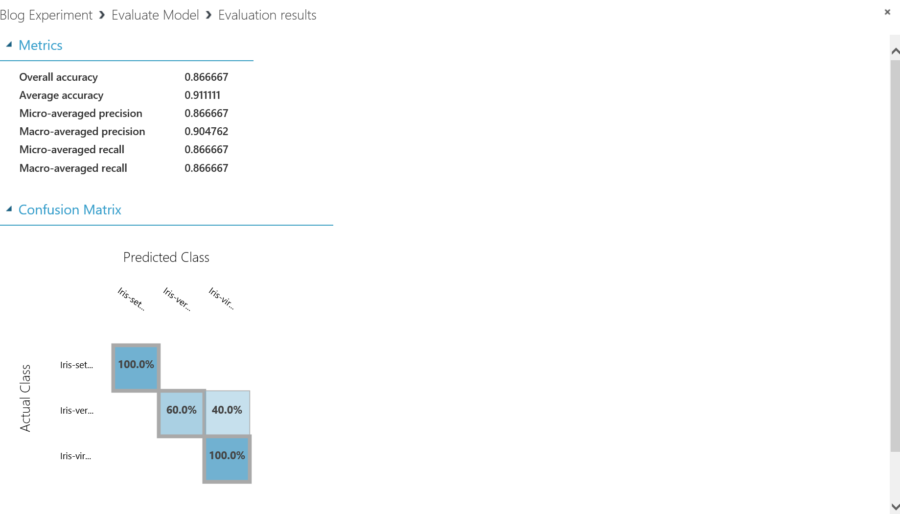
Evaluation View
Retrain results
The accuracy was low, 86.66%. This would be unacceptable in most cases. To increase the accuracy there are a couple of things to try.
-
Add more data to the dataset
-
Try a different machine learning algorithm.
Within the experiment, the initialization model can be easily changed to a different machine learning algorithm.
From the Machine learning section, expand Initialize Model and expand Classification. From here drag the Multiclass Decision Forest action to the page and connect it where the Multiclass Neural Network was connected to the train model.
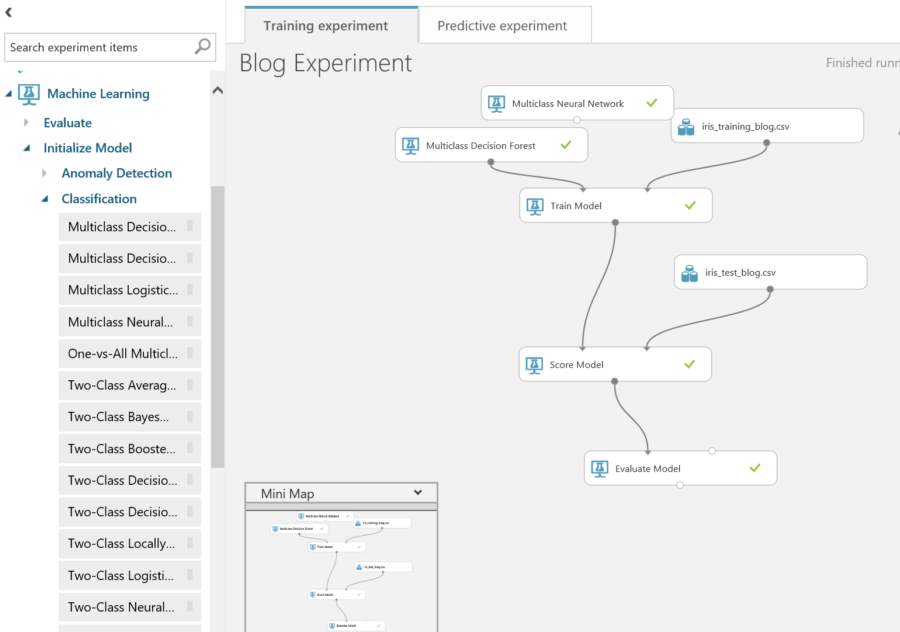
Run experiment again and view results.

For this experiment the datasets were very small. Only 150 items were used to train the dataset. This is skewing the results and has a large effect on what the outcome is. The more items in the dataset the more accurate the results. If the experiment is 100% accuracy then it is important to review the data and make sure it is clean, and if it is correct then machine learning may not be necessary for data to be evaluated, and a different algorithm might suit the dataset better.
Create a web service
Once the desired results are achieved, the trained model can now be exposed as a web service. At the bottom of the experiment, select Set up web service. And select Predictive Web Service.
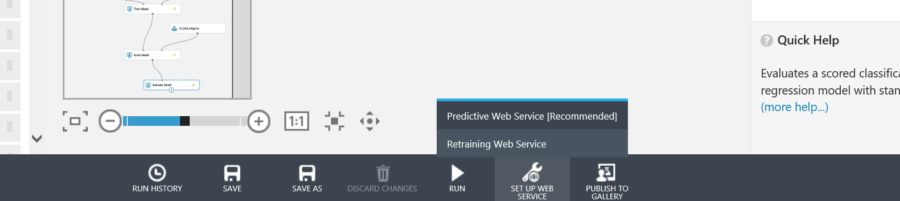
When finished the screen should look something like this
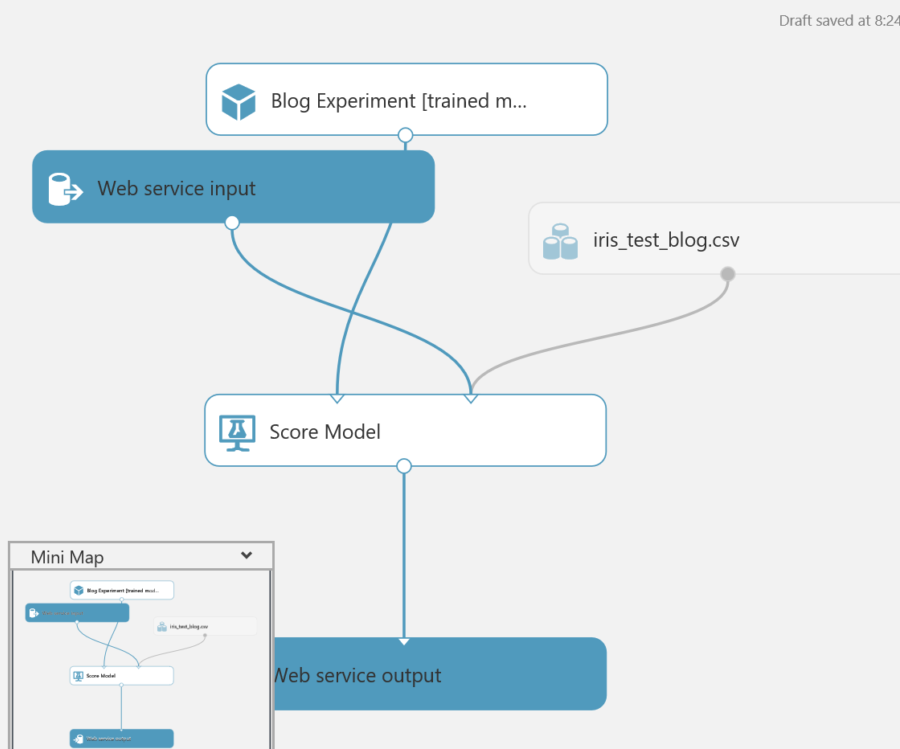
Before deploying, it is important to run the web service to make sure everything is setup correctly.

When everything passes, hit deploy web service. When the web service is finished deploying the service will be available on the web service tab. In the web service tab there are many features including the API Key, and tests for the web service. How to call and consume the web service can also be found by clicking the request/Response section.
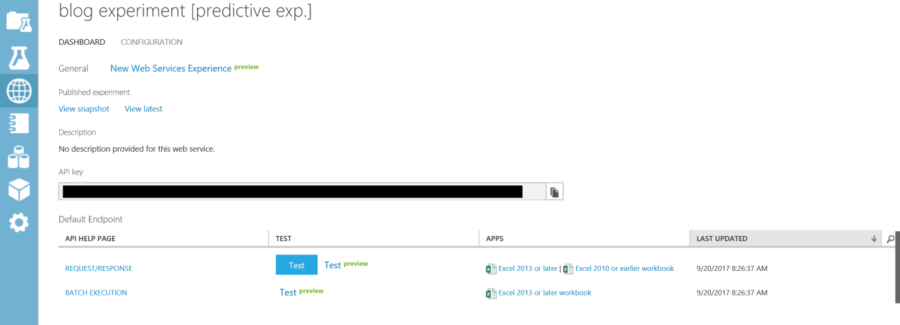
•••
References
Datasets: http://archive.ics.uci.edu/ml/... (training)
https://en.wikipedia.org/wiki/... (test)
Azure Machine Learning: https://studio.azureml.net/
Information and material in our blog posts are provided "as is" with no warranties either expressed or implied. Each post is an individual expression of our Sparkies. Should you identify any such content that is harmful, malicious, sensitive or unnecessary, please contact marketing@sparkhound.com
Share this
.png)
Best Methods for Deploying Data Analytics & Machine Learning
-1.png)
Critical Skills for Data Scientists in the Machine Learning Revolution
-2%EF%B9%96width=1920&height=1080&name=Photo%20(1)-2.png)